干掉盲目分流的瓶颈:看 Octopus Energy 如何搞定大规模邮件客服支持
早上 8:30,你打开共享邮箱。里面躺着 142 封未读邮件。
一半是在要发票副本,四分之一在抱怨物流。剩下的全是乱七八糟的东西:账号写错的、打错字的、还有账单纠纷。
你的运营团队在解决任何一个实际问题之前,得先花整整四个小时去读邮件、打标签、转办。
在能源危机期间,Octopus Energy 也遇到了这种噩梦,而且规模大得多。他们招人的速度压根赶不上邮件增长的速度。于是,他们在自己的 Kraken 平台里搞了一个叫 Magic Ink 的生成式 AI 工具,专门负责分拣邮件和起草回复。
现在,这个工具处理了他们 45% 的客户邮件。AI 生成的邮件客户满意度高达 80%,而人工客服只有 65%。
他们是怎么做到的?你作为中小企业老板,该如何搭建同样的架构?
「盲目分拣」的瓶颈
所谓「盲目分拣」瓶颈,就是你花钱雇人,在真正解决问题之前,先在那儿读邮件、分类、手动翻找数据。这全是隐形成本。
每天早上,你的财务助理打开一封邮件。上面写着:「我的账单不对。」没写账号。发件人的邮箱地址和 Xero 里的也对不上。
助理停下手头的活儿,开始在 CRM 里搜域名。搜出来三个不同的联系人。再去 Xero 里交叉比对公司名。最后终于找到了账户,打开最新发票,才发现客户看的是三个月前的形式发票。
十五分钟过去了。没创造任何价值。助理才刚刚搞清楚状况,准备开始打字回复。
这就是中小企业客户服务的现状:工作内容不是「解决问题」,而是「找资料来理解问题」。
当你规模扩大时,这个瓶颈也会跟着线性增长。客户翻倍,邮箱里的噪音就翻倍。你招更多的新人,他们整天就像个「人工路由器」,把邮件拖进文件夹,在浏览器标签页之间复制粘贴数据。
这太磨人了。没人找工作是为了在 Outlook 和 Xero 之间当个人肉数据搬运工。
老板们看着工资单蹭蹭涨,回复速度却越来越慢。本能反应是买个 AI 工具来解决。但因为他们没搞懂这个瓶颈的真实逻辑,第一次尝试几乎都会失败。他们总想自动化「写回复」,其实该自动化的是「读邮件」。
为什么显而易见的方案会失败
在共享邮箱上随便套个 Zapier 插件是没用的。因为这种做法把客户邮件当成了结构化数据,但邮件本质上是混乱的。
大多数中小企业都会试这种法子:在 Zapier 里设个 Gmail 触发器,连上 OpenAI。写个提示词(prompt)说:「读这封客户邮件,写个礼貌的回复。」然后把草稿塞回 Gmail。
这简直是灾难。
AI 根本没有上下文。它不知道客户的余额,不知道物流状态。它只知道邮件里那几行原始文本。结果就是,它会一本正经地胡说八道,写出一封语气礼貌但内容全错的回复;或者写一堆废话,管客户要账号。
你惹火了客户,项目黄了,然后你得出结论:AI 还没到时候。
失败的原因不只是提示词写得烂。这是基础自动化工具处理非结构化文本时的结构性失败。Zapier 原生的邮件解析依赖于固定的字段 and 可预测的格式。
如果客户回复了一长串邮件,但把正文埋在三段企业签名下面,解析器就瞎了。如果供应商在邮件签名的深处放了一个自定义联系字段,提取出来的可能就是个空值。
自动化跳过了这一步,工单死在了系统里。你直到月底客户留了一星差评才会发现。
在我调研中小企业运营的经验里,我总能看到这种对「单步 AI 调用」的盲目依赖。老板们想要一个魔盒,读一下邮件就能把问题全解决了。
你需要的是一套系统,而不是魔盒。在让 AI 写一个字之前,你得先从数据库里抓取实时上下文。如果你不把 ChatGPT 连进你的业务数据,那一个月 £25 的订阅费永远替代不了一个年薪 £35k 的员工。
真正管用的方法

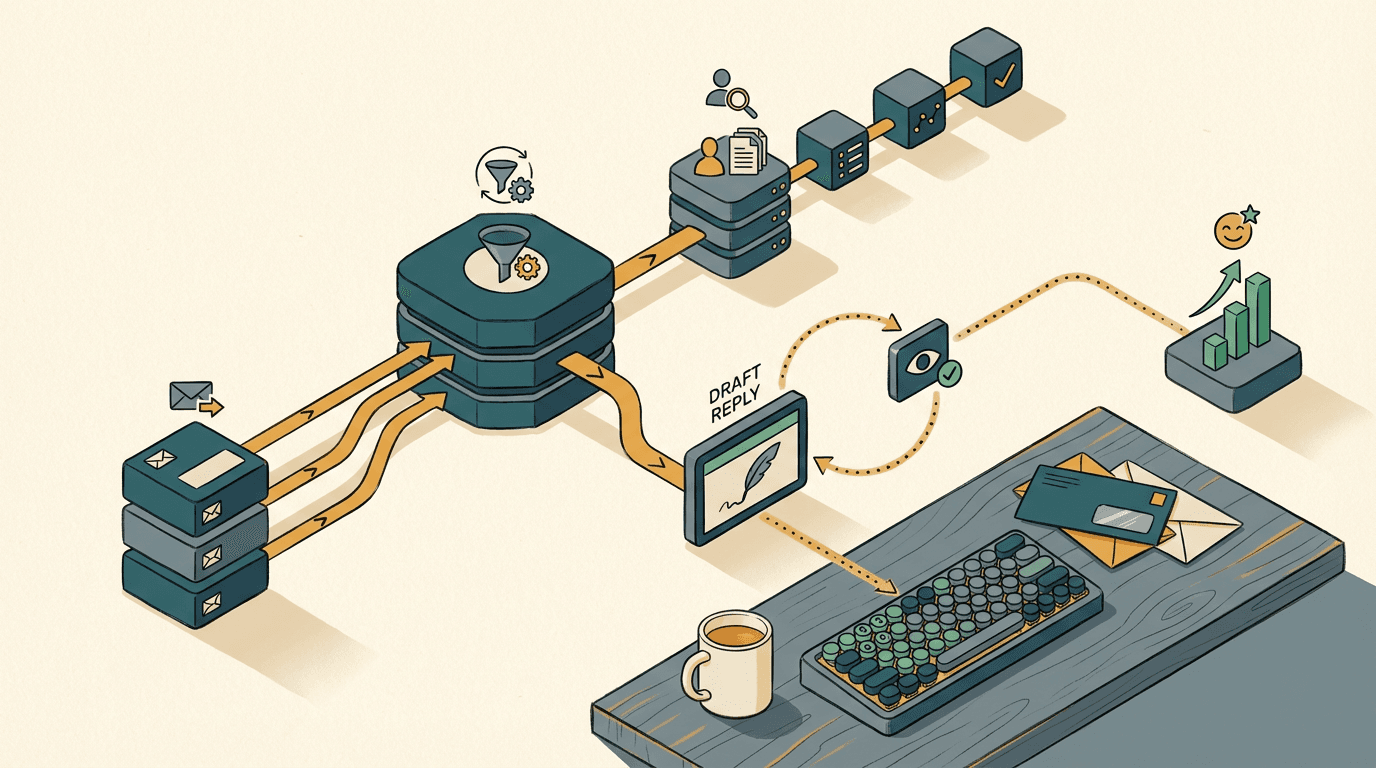
一套管用的 AI 分拣系统,要把「提取意图」和「生成回复」分开,通过不同的 API 调用从数据库里抓取实时信息。
Octopus Energy 成功是因为他们把 AI 直接集成到了平台底层。它能原生获取最多的上下文,从整个客户生命周期里抓取数据 (https://www.techuk.org/resource/ai-adoption-case-study-kraken-s-generative-ai-tool-for-customer-service-helping-octopus-energy.html)。
你可以用 Make 或 n8n 复制这套架构。
以下是实际运行的步骤:
第一步是接入。Make 里的 webhook 截获 Gmail 或 Outlook 的新邮件。它会剥离 HTML、图片和签名垃圾,只留下纯文本。
第二步是提取。把干净的文本通过 API 发给 Claude。别让 Claude 写回复。你要强制它输出严格的 JSON 格式,提取三样东西:客户意图、紧急程度、以及任何关键信息(比如发票号或公司名)。
第三步是检索上下文。Make 拿着提取出的发票号去查 Xero。它抓取实时余额、到期日和明细。然后去查 HubSpot,找客户经理的名字和最近的工单记录。
第四步是生成。第二次调用 Claude。把原始邮件、Xero 数据和 HubSpot 数据全喂给它。这时候,再让它起草回复。
因为它掌握了事实,写出来的回复会非常精准。它把草稿存在你的客服系统里。人工读一遍,点个确认,搞定。
举个真实场景:客户发邮件说因为住院了,自动扣款失败。
因为系统抓了 Xero 的数据,AI 知道余额是 £150,也知道账户历史。它生成的回复会主动暂停催收。
Octopus Energy 的创始人 Greg Jackson 提到,生成式 AI 在这种时刻「极大地增强了人的力量」(https://www.enlit.world/news/generative-ai-has-turbocharged-the-power-of-the-human-says-octopus-energy-founder-greg-jackson/)。他看到 AI 给生病客户写的草稿开头是:「在这种时候,有比能源账单更值得担心的事。首先,希望您的身体早日康复。」
AI 的结尾同样充满同理心。这能行得通,是因为数据是准确的。
你自己搭这套东西,预计需要 2-3 周。成本在 £6k 到 £12k 之间,取决于你现有的 Xero 和 HubSpot 集成有多乱。
这里已知的坑是 AI 可能会乱编一个政策日期。解决办法就是「人工审核」。AI 写草稿,人来审批。这样既消灭了分拣瓶颈,又不会砸了招牌。
哪里会掉链子
如果你的核心客户数据存在没有开放 API 的系统里,AI 分拣就彻底玩不转了。
我在动手做之前都会先检查这点。如果你的数据被困在本地的老旧数据库里,大模型(LLM)就没法抓取实时上下文。它查不了余额,看不了物流。
没有这些背景,整套架构就塌了。你又回到了那种注定失败的老路:一个只会问烦人问题的通用聊天机器人。
非结构化附件也是个坎儿。如果你的发票是从老财务系统里扫出来的 TIFF 图片,你得先加一步 OCR(文字识别)。
一旦加入 OCR 来识别烂字迹或低分辨率扫描件,错误率会从 1% 飙升到 12% 左右。AI 提取了错误的发票号,去 Xero 查一个不存在的东西。自动化断了,最后还是得人工介入。
另一个雷区是强监管的咨询。如果客户在问具体的法律或财务合规建议,千万别让 AI 去写技术细节。它一本正经胡说八道的风险太高了。
如果你的数据没法通过干净的 API 访问,先修好你的数据层。别想着用聪明的 LLM 去掩盖烂透了的数据库,那只会让它崩得更快。
要避开的三个坑
你现在知道一套管用的 AI 分拣系统是怎么运作的了。开始动手时,避开这些陷阱:
- 别让 AI 自动发送。永远保持人工审核。如果你跳过草稿阶段,让 API 直接给客户发邮件,早晚会有幻觉内容发出去。AI 可能会承诺你根本没有的退款,或者编造一个交货日期。把 AI 的输出作为草稿存进客服系统或 Gmail。团队检查、修改,然后点发送。
- 别用一个提示词搞定全程。别贪省事,把提取、推理和起草全塞进一次 API 调用里。让大模型一次干太多活,它会分心,幻觉率会飙升。把任务拆开。用一个 JSON 模式的调用来提取数据。运行 API 查询。然后再用一个全新的调用来写回复。
- 别先拿愤怒的投诉练手。从高频、低情绪的工单开始。自动化那些要发票副本、查物流状态、重置密码的请求。这些只需要简单的数据库查询,没有情绪风险。如果 AI 把重置密码的草稿写错了,人工删了就行。把复杂的、来回扯皮的纠纷留给资深员工,直到系统证明了自己再放手。
订阅获取 UK AI 洞察。
针对英国企业的 AI 实战内容 —— 拆解、教程、监管解读。随时取消。
随时取消。