你走进运营办公室,看到资深项目经理正盯着分屏显示器。左边是一个新承包商发来的 45 页供应商合规 PDF;右边是一个乱糟糟的 Excel 风险跟踪表,从 2024 年起就没彻底更新过。她正在手动核对供应商的保险条款,看赔偿限额够不够公司即将开展的物流项目要求。
核对一个供应商就要花她两个小时。公司现在有 40 个项目在跑,算算这笔账,你正在把高薪聘请的人才浪费在行政性的「打勾勾」工作上。你买了 Microsoft 365 Copilot,本指望它能「读读文件」,但现实是,你的团队还在干这些苦力活。AI 的承诺和运营一线的现状之间,隔着一条鸿沟。每一天,你的团队都陷在这些一模一样的重复检查里。
合规拖累税
「合规拖累税」是一笔隐形成本:你付着高薪,却让资深员工去手动核实项目合规性、风险登记册和供应商文件是否符合内部标准。在任何成长的企业中,这都是运营利润的无声杀手。你花 £60k 年薪请运营经理来设计更好的交付系统,结果她每周有 30% 的时间在拿 PDF 跟总表做交叉比对。
这笔「税」之所以存在,是因为项目审计本质上就是一种带着焦虑感的「文字匹配游戏」。公司需要百分之百确定分包商有正确的证书,或者项目阶段在发布前达到了内部质量关卡。因为赌注很高,你只能派人盯着。
但人的眼睛会累。当一个运营经理读到本月第 14 份风险评估报告时,她会扫视。她会漏掉一个缺失的日期,会忽略一个过期的资质。讽刺的是,靠人工审核来搞合规,你其实是在支付溢价的同时,反而增加了风险敞口。
结果就是,这个瓶颈会随着你的收入增长而线性扩张。每增加一个新项目,就需要更多的人工检查。不招更多的行政人员你就没法扩张,而你的资深团队则被困在无休止的文件审查循环里。
最后,你那群高素质的团队变成了高薪的数据录入员,被「合规拖累税」吃得干干净净。这事儿消磨士气,也吞噬利润。厉害的运营者想做的是建设和优化,而不是给第三方的文书当人工拼写检查员。
为什么显而易见的办法没用
给运营团队买 ChatGPT Plus 账号来查合规文件,是自动化错误最快的方式。大多数中小企业都会先试这招。他们觉得聊天界面能处理死板的合规工作。
他们错了。
实际情况是这样的:一名财务助理把 50 页的承包商协议上传给 ChatGPT,然后输入:「检查这份协议是否符合我们的项目审计标准。」大语言模型(LLM)读了文件,自信满满地表示一切正常,于是助理在跟踪表里打了个勾。
但 LLM 压根没检查你的内部标准,因为它根本不知道标准是什么。它只是把文件跟通用的商业规范做了个模式匹配。就算你把标准粘贴到提示词里,消费级 AI 工具也会有「注意力漂移」。如果供应商的责任条款埋在第 42 页一个带有误导性的标题下,标准的 ChatGPT 提示词会直接跳过它。这种界面是为了聊天设计的,不是为了严谨。
另一个常见的坑是想用基础的 Zapier 工作流把这事儿串起来。你设了一个 Zap,当 Gmail 文件夹收到新 PDF 时触发,把文字发给 OpenAI,然后更新 Google Sheet。这东西跑不到一周就会崩。
Zapier 标准的文本提取功能会把复杂的 PDF 表格变成一串乱码。当 AI 试图解析多列风险登记册时,行数会对不齐。它会悄悄批准一个关键风险,而你只有在外部审计时才会发现。
根据我的经验,靠非结构化的聊天提示词来做结构化的合规检查,只会给你一种「搞定了」的错觉,同时悄悄埋下灾难性的盲点。你以为你实现了运营现代化,其实只是用一个快速、自大的文本生成器替换了一个慢速、准确的人类。当一个不合规的供应商溜掉时,责任还是得你来扛。
真正管用的方法

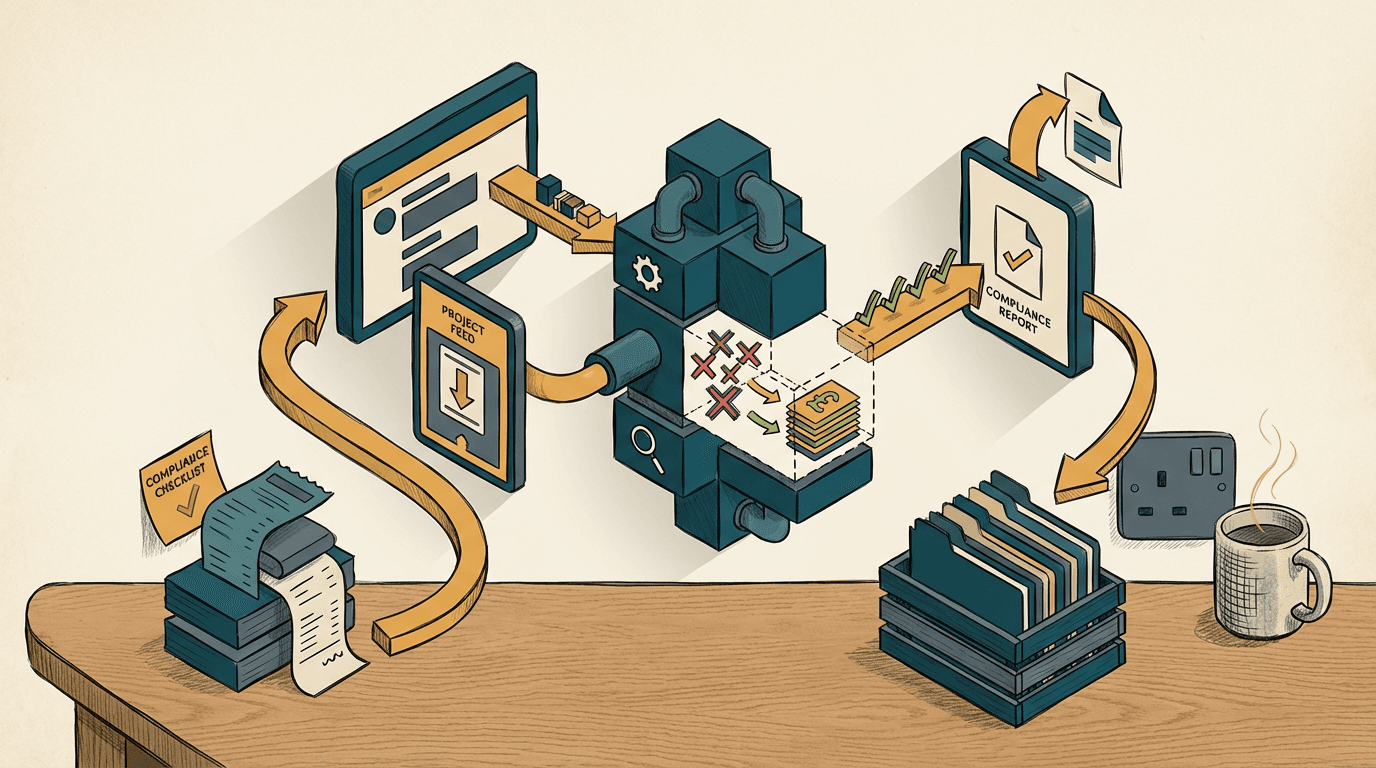
真正的项目审计自动化需要一条死板的数据管道:摄取文件、可预测地提取数据、根据硬编码的框架进行评估。你要构建的是一个让数据步步推进的系统,把聊天界面彻底踢出去。
这是一个具体的方案:供应商发来一封邮件,标题是「第三季度合规包」,带个 PDF 附件。一个 n8n webhook 截获邮件并剥离附件。系统不会把原始文本直接扔给 LLM,而是先用专门的 OCR 工具映射文件结构。
然后,它向 Claude 3.5 Sonnet 发起 API 调用,强制要求输出严格的 JSON 格式。提示词不会问「这东西好不好?」,而是要求 Claude 提取五个特定的数据点:有效期、责任限额、主体名称、风险评分和缺失条款。
n8n 工作流会根据你的业务规则评估那个 JSON 数据包。如果责任限额低于 £1M,自动化程序会打上标记。然后它会 PATCH(更新)Xero 里的供应商记录,把自定义字段改为「需要人工审核」,并在 Slack 频道里弹个消息,指明不符项具体在第几页。只有在规则被打破时,人才需要介入。
如果你压根不想搞定制开发,专门的平台也终于成熟了。像 FAST (Firewood) 这种工具就是为此而生的。techUK 最近的数据显示,使用 FAST 进行项目审计能减少 20% 的审核时间,并将每次审计的行政成本降低高达 35% [来源](https://www.techuk.org/resource/ai-adoption-case-study-transforming-project-assurance-with-fast-firewood.html)。它之所以管用,是因为 AI 被限制在审计框架内,它不是一个开放式的助手。
搭建定制的 n8n 管道大约需要 2-3 周,成本在 £6k 到 £12k 之间,具体取决于你现有的供应商数据有多乱。主要的失败模式是意料之外的文件格式,比如供应商发了个加密文件,或者发了个装满 JPEG 图片的压缩包。
对付这事儿,你可以在 n8n 里建一条失败路径,直接秒回发件人:「我们的自动化系统读不了你的文件,请重新发送未加密的 PDF。」这把行政负担甩回给了供应商,本来就该他们干。
你还得盯着 API 成本。如果不先过滤掉噪音,把几百个巨大的 PDF 全塞给高级模型,账单会爆掉。聪明的管道只会把相关的页面发给 LLM,忽略那 30 页永远不变的格式化条款。
哪里会掉链子
如果你的进项文件根本读不了,或者你的内部合规规则全靠「人的直觉」,那自动化审计就彻底废了。
这招不是魔法。在写一行自动化代码之前,你得先审计一下你的文件摄取流程。
如果你收到的项目文件是老旧财务软件扫出来的 TIFF 图片,或者是手写的现场安全日志,那你得先搞一层很重的 OCR。一旦涉及手写体或低分辨率扫描件,提取错误率会从 1% 飙升到 12% 左右。到那时候,自动化产生的异常处理工作比它省下的时间还多。你花在修 OCR 错误上的时间,比直接读文件还长。
如果你的内部合规规则是主观的,这事儿也跑不通。如果你的审计框架依赖于运营经理对供应商风险状况的「感觉」,API 模拟不了那个。AI 提取的是事实,并将其与规则进行比对。
如果你的规则不能记录为二进制的阈值(比如特定的日期、特定的金额、或者是否存在特定的命名条款),系统就会失败。在自动化检查之前,你必须先标准化你的定义。如果你现在的流程是建立在直觉之上的,这世上没有任何软件能救得了它。
问题不在于 AI 能不能读懂供应商文件,而在于你有没有那份定力,不再把合规当成一种「手艺活」,而是把它当成一条数据管道。你的资深团队每花一小时去手动核对保险限额和项目里程碑,就少了一小时去解决真正的运营瓶颈。自动化项目审计苦力活的技术已经在这儿了,而且中小企业的预算完全负担得起。但这需要你远离那些消费级聊天机器人,去构建死板、可预测的系统。工具管用,API 也很便宜。一旦你剥离了行政冗余,你终于能看到你的运营团队到底能爆发多大的战斗力。
订阅获取 UK AI 洞察。
针对英国企业的 AI 实战内容 —— 拆解、教程、监管解读。随时取消。
随时取消。